
Транслятор – это программа, которая переводит исходную программу в эквивалентную ей объектную программу. Если объектный язык представляет собой автокод или некоторый машинный язык, то транслятор называется компилятором.
Автокод очень близок к машинному языку; большинство команд автокода – точное символическое представление команд машины.
Ассемблер – это программа, которая переводит исходную программу, написанную на автокоде или на языке ассемблера (что, суть, одно и то же), в объектный (исполняемый) код.
Компиляторы пишутся как на автокоде, так и на языках высокого уровня. Кроме того, существуют и специальные языки конструирования компиляторов – компиляторы компиляторов.
Компилятор компиляторов (КК) – система, позволяющая генерировать компиляторы; на входе системы – множество грамматик, а на выходе, в идеальном случае, – программа. Иногда под КК понимают язык программирования, в котором исходная программа – это описание компилятора некоторого языка, а объектная программа – сам компилятор для этого языка. Исходная программа КК – это просто формализм, служащий для описания компиляторов, содержащий, явно или неявно, описание лексического и синтаксического анализаторов, генератора кодов и других частей создаваемого компилятора. Обычно в КК используется реализация схемы т.н. синтаксически управляемого перевода. Кроме того, некоторые из них представляют собой специальные языки высокого уровня, на которых удобно описывать алгоритмы, используемые при создании компиляторов. Логическая структура компилятора
Рисунок 1 – Схема компилятора
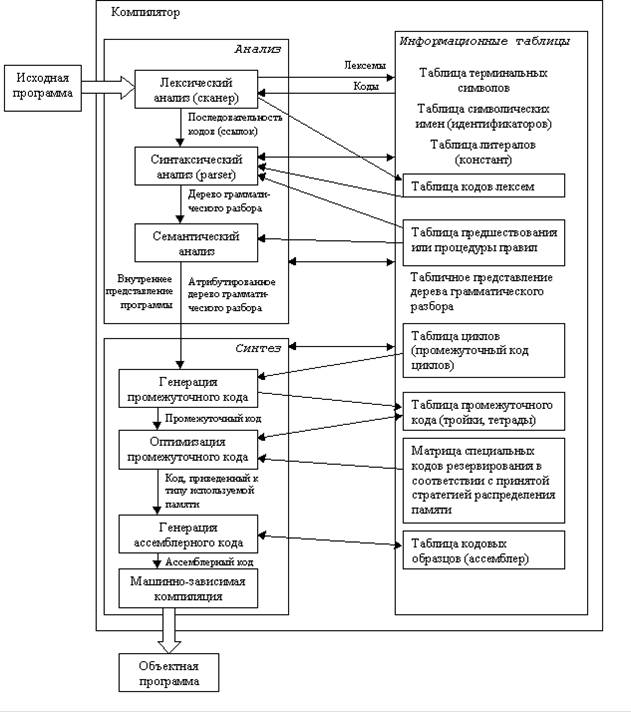
Исходная программа – текст программы на языке высокого уровня (например Паскаль), который должен быть переведен в машинный код.
Информационные таблицы – самостоятельные структуры, заранее заполненные (таблица терминальных символов), а также заполняющиеся в ходе лексического анализа и дополняющиеся во время работы.
Лексический анализатор выполняет распознавание лексем языка и замену их соответствующими кодами. Под лексемами понимаются элементарные единицы, входящие в структуру предложения языка, такие как ключевые слова, константы, имена и т.п. Правильность задания структуры предложения языка на фазе лексического анализа не выполняется. Результатом является поток лексем (кодов – ссылок на таблицы), эквивалентный исходному тексту.
Синтаксический анализатор необходим для того, чтобы выяснить, удовлетворяют ли предложения, из которых состоит исходная программа, правилам грамматики этого языка.
Семантический анализ. На этом этапе осуществляется контроль типа и вида всех идентификаторов и других операндов.
Генерация промежуточного кода. Происходит преобразование исходной программы в промежуточную (например, польскую) форму записи.
Оптимизация промежуточного кода – выделение общих подвыражений и вычисление константных подвыражений.
Фаза оптимизации предназначена для уменьшения избыточности программы по затратам времени и памяти. В зависимости от критериев проектирования транслятора данная фаза обработки программы может исключаться из цикла обработки программы.
Распределение памяти. На этом этапе выделяются конкретные адреса пользователя под переменные, которые генерируются компилятором.
Генератор объектного (ассемблерного) кода – выполняет подстановку кодовых образцов на выходном языке, соответствующих промежуточным кодам программы. Генератору кода могут не требоваться шаблоны, он весь может быть реализован в процедурном виде.
Машинно-зависимая компиляция. Зависит от того, какие используются регистры. Работа этой процедуры зависит от соглашений, принятых для исполняемой части программы. Например, выделяется базовый регистр для текущей активной записи в стеке.
На всех этих этапах происходит работа с различного рода таблицами. В частности, для каждого блока (если таковые существуют в языке) идентификаторы, описанные внутри, запоминаются вместе со своими атрибутами. Условно все эти этапы можно изобразить следующим образом:
Очевидна зависимость структуры компилятора от структуры ЭВМ, точнее, от имеющейся производительности системы. Например, при малой памяти увеличивается количество проходов компиляции (т.н. многопроходные компиляторы), а при наличии памяти большого объема можно все этапы компиляции произвести за один проход (и тогда мы имеем дело с однопроходным компилятором).
Далее мы рассмотрим некоторые из этих составных частей процесса компиляции.
Лексический анализатор представляет собой модуль разбора текста программы. Разбор происходит в зависимости от имеющихся у него в памяти терминальных символов и правилами определения типов данных. Каждый язык имеет свои ограничения по типам данных, допущения и особенности создания (строения) конструкций, применению операторов и т.п. При работе сканера используются три таблицы: таблица терминальных символов, таблица символических имен и таблица литералов – это заполняемые таблицы. Таблица терминальных символов хранит все ключевые слова и специальные символы используемые в языке, а также коды, соответствующие каждому символу. Таблица символических имен заполняется в процессе разбора текста программы и хранит в себе имена идентификаторов (символических имен). Таблица литералов также заполняется в процессе разбора программы и хранит в себе литералы: численные и строковые значения, с указанием типов данных и относительных адресов.
Распределение по таблицам происходит следующим образом.
Сканер в процессе анализа текста программы выделяет один из элементов текста и сравнивает с каждым терминальным символом. Если такой символ найден, то в выходной код передаются код таблицы и спецификатор (номер строки в таблице). В случае если этот элемент не является терминальным символом проверяется, является ли он идентификатором (первый символ обычно буква, остальные могут быть либо буквой, либо цифрой), если такой определен, то данный элемент заносится в таблицу символических имен, а к выходному коду добавляется пара численных значений: номер таблицы и спецификатор найденного элемента. В случае если такой элемент в таблице уже имеется, то в выходной код заносится номер таблицы и его спецификатор. В таблицу литералов заносят численные, строковые и иные определенные языком значения. При этом распознается тип значения и тут же заполняется относительная таблица адресов.
Выходной код, сформированный сканером, передается на следующую стадию обработки – синтаксический анализ.
Таким образом, алгоритм работы простейшего сканера можно описать так:
- просматривается входной поток символов программы на исходном языке до обнаружения очередного символа, ограничивающего лексему;
- для выбранной части входного потока выполняется функция распознавания лексемы;
- при успешном распознавании информация о выделенной лексеме заносится в таблицу лексем, и алгоритм возвращается к первому этапу;
- при неуспешном распознавании выдается сообщение об ошибке, а дальнейшие действия зависят от реализации сканера – либо его выполнение прекращается, либо делается попытка распознать следующую лексему (идет возврат к первому этапу алгоритма).
Работа программы-сканера продолжается до тех пор, пока не будут просмотрены все символы программы на исходном языке из входного потока.
Список использованной литературы
- Бек Л. Введение в системное программирование.: Пер. с англ. – М.: Мир, 1998.
- Грис Д. Конструирование компиляторов для цифровых вычислительных машин. – М.: Мир, 1975.
- Карпов В.Э. Классическая теория компиляторов. – http://itlab.net.ru/ materials/compiler/compiler.html
- Креншоу Д. Давайте создадим компилятор! – http://kit.kulichki.net/ crenshaw/crenshaw.html
- Основы компиляции. http://structur.h1.ru/compil.htm
© С.Б. Мхамметаманова, 2016.
Свежие комментарии