
Карачаево – Черкесский государственный университет
им. У.Д.Алиева, г. Карачаевск
Реальные базы данных промышленного масштаба содержат миллионы записей, данные которых описывают состояния и взаимосвязи многих и многих объектов реального мира. Требования, предъявляемые пользователями к автоматизированным или автоматическим системам, обрабатывающим эти данные, обусловливают и требования к параметрам подсистем внешней памяти, в первую очередь, предполагают высокую оперативность доступа. Важной особенностью здесь является то, что архитектура систем и технологий управления данными непосредственно связана с двумя следующими значительными, хотя и противоположными обстоятельствами:
- непредсказуемой вариантностью представления данных в прикладной
программе, зависящей от разнообразных особенностей пользовательских
задач; - жесткостью технических решений устройств внешней памяти,
выражающейся в функциональной простоте 12 операций и ограниченности
форм представления данных.
Требование операционной простоты определяется производственными и экономическими причинами: устройство должно быть надежным в использовании и дешевым в изготовлении (т. е. содержать минимум механических компонент и сложной логики).
Функциональная ограниченность управления данными, кроме того, диктуется еще и требованием унифицированности: устройство должно одинаково эффективно и стандартным способом использоваться в составе различных вычислительных и операционных систем, даже если со временем отдельные компоненты систем будут принципиально меняться.
Высокая эффективность решений в области обработки данных достигается введением промежуточных слоев специализированных технических и программных средств. Характер проблем и архитектурно-технологические решения такого рода достаточно полно иллюстрируются приведенной на рис. 1 примерной схемой реализации операций ввода-вывода
— взаимодействия прикладной программы с компонентами операционной
системы и устройствами внешней памяти. Здесь специализация компонент
выражается в том, что по существу каждый из них реализует различные
способы работы с потоком данных (и в частности, его фрагментацию на
блоки), что и обеспечивает, с одной стороны, необходимый уровень
декомпозиции и идентификации логических/физических записей, а с другой
— независимость физического и логического уровней представления данных.
Здесь термины логический и физический отражают различия аспектов
представления данных. Логическое представление указывает на то, как
данные используются в прикладной программе, т. е. отражают логику
обработки. Физическое представление — это то, как данные хранятся на
физическом носителе.
Будем считать логической записью идентифицируемую (именованную) совокупность элементов или агрегатов данных, воспринимаемую прикладной программой как единое целое при обмене информацией с внешней памятью (по крайней мере, для операций ввода-вывода).
Физической записью будем считать совокупность данных, которая может быть считана или записана как единое целое одной командой ввода-вывода. Важно, что для компонент различного уровня в технологической цепи ввода-вывода состав и структура физической записи может быть разной.
Структура данных и их взаимосвязь в случаях логического и физического представления могут не совпадать. Например, а) одна физическая запись может включать несколько логических; б) порядок следования элементов данных в физической записи может быть изменен для оптимизации использования пространства памяти. То есть, если логическая структура может варьироваться в широком диапазоне и даже представляться, например, вариантными записями, то физическая — практически всегда представлена жесткой структурой, причем в значительной степени определяемой типом носителя.
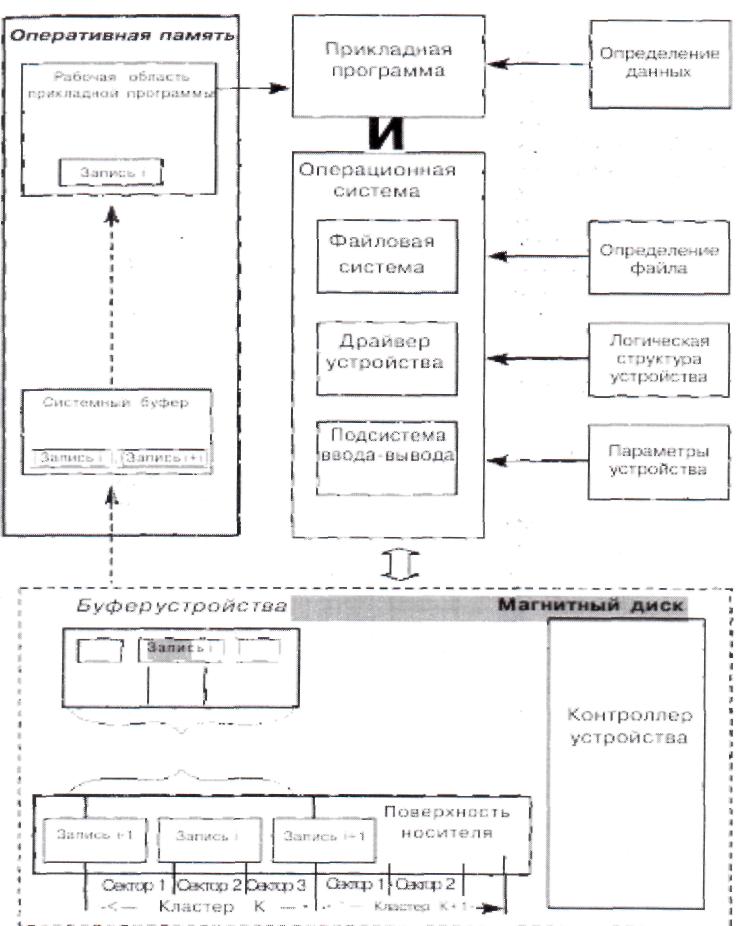
Примерная схема организации файлового ввода-вывода
Рассмотрим для представленной на рис. 1 схемы ввода-вывода способы адресации и последовательность операций выборки даннных, обеспечивающих чтение прикладной программой с тома внешней памяти (например, магнитного диска ПЭВМ) некоторой произвольной (1-ой) записи. Отметим еще раз, что «специализация» компонент, участвующих в операциях ввода-вывода, выражается прежде всего в используемом способе адресации.
Прикладная программа использует одномерную (или сводимую к одномерной) сквозную адресацию данных на уровне логических записей: запись определяется номером, например, соответствующим порядку их размещения.
Система управления физическим вводом-выводом (в рассматриваемом примере — ВЮ8 ПЭВМ) использует трехмерную систему координат: адрес записи составляется из номера дорожки, номера головки чтения-записи (номер поверхности) и номера сектора. Операционная система же использует одномерную сквозную систему координат: сектора нумеруются от края диска к центру последовательно, причем сначала в рамках одного сегмента цилиндра (кластера), далее сектора следующего сегмента дорожки, после чего происходит переход к следующей дорожке.
Этот способ адресации и, соответственно, порядок использования пространства отчасти отражает специфику аппаратных решений, ориентированных на временную оптимизацию операций ввода-вывода: большее количество данных будет считано при одном обращении к диску за счет одновременного обращения через головки чтения-записи к данным, размещенным на параллельных дорожках в одном секторе одного цилиндра. Фиксированное количество битов, равное размеру сектора, определенного при разметке, умноженному на число головок, будет прямо (без дополнительной обработки, например, проверки логических условий конца файла или записи) передано в буфер оперативной памяти устройства или операционной системы. [2]
Таким образом, если система адресации в прикладной программе является относительной и отражает логику взаимосвязи записей (например, порядок создания файла), то для подсистем ввода-вывода она является абсолютной и определяется физическим форматом носителя: размером сектора, количеством секторов на дорожке, количеством поверхностей и дорожек и т. д. При этом независимость от особенностей физического размещения и механизма адресации обеспечивается на уровне логической структуры носителя. Например, логически последовательная выборка записей файла обеспечивается таблицей размещения файлов, определяющей используемое файлом пространство как цепочку кластеров, физически находящихся в любой доступной части диска. Доступ к файлу производится по идентификатору (составному имени) через систему каталогов, связывающих идентификатор файла с началом цепочки указателей на кластеры данных в таблице размещения файлов. Кроме того, логическая структура содержит (в составе загрузочной записи) информацию, идентифицирующую пространство в целом, а также данные, определяющие физическую структуру (физический формат носителя, рассмотренный ранее).
В общем случае операция чтения физической записи включает
следующие действия.
- Определение адреса записи в координатах устройства (например, для файлов с записями фиксированной длины — пересчет номера нужной записи в относительный адрес сектора и далее определение абсолютного номера сектора на диске).
- Перемещение головки чтения в соответствующую координату:
позиционирование к дорожке и сектору на дорожке, складывающееся из двух
действий — собственно радиального перемещения головки на расстояние от
текущего положения до нужной дорожки и ожидания подхода указанного
сектора вращающегося диска к позиции, где находится головка. Следует
также отметить, что высокая плотность записи данных означает, что
промежуток между секторами и дорожками сравнительно мал (сопоставим с
погрешностями механизма перемещения и тепловым расширением), и
поэтому правильность позиционирования определяется по служебным
данным. [1]
Если контроллер не успевает завершить обработку передачи и подготовиться к передаче данных, размещаемых на физически следующем
секторе, то придется ожидать завершения полного оборота диска. С целью исключения таких потерь диск форматируется так, что логически последовательные секторы разделены одним или несколькими физическими секторами (коэффициент чередования), тогда контроллер будет готов выполнить операцию со следующим логическим сектором, не ожидая дополнительного оборота.
- Пересылка данных, расположенных в области кластера, в буфер, который физически может быть как частью устройства, гак и областью оперативной памяти.
- Завершение операции (проверка корректности чтения, например по контрольной сумме) и возврат управления ОС для обработки считанных данных.
- Выделение системой данных, относящихся к затребованным записям. Причем во многих случаях в системный буфер считываются не только данные логической записи, нужные прикладной программе, но и соседние. Это позволяет сократить суммарные затраты времени при чтении нескольких записей, исключив наиболее долгую операцию позиционирования. Указание на такое блокирование может выдаваться явно прикладной программой при открытии файла или операционной системой, использующей собственные механизмы кэширования для оптимизации ввода-вывода.
- Передача в рабочую область прикладной программы данных запрошенной ею логической записи или указателя на соответствующую область памяти в системном буфере.
В этой последовательности наиболее медленными операциями являются механическое позиционирование головок и чтение данных с поверхности носителя (выполняемые на порядки медленнее, чем операции пересылки). Поэтому выигрыш во времени может быть получен только в случае выполнения ряда запросов на доступ к данным, причем экономия может достигаться следующими путями. [2]
- Суммарным сокращением перемещения головок за счет организации
такой последовательности обращения к записям (или такого порядка их
физического размещения), когда перемещение от текущего положения к
следующему будет минимальным. - Формированием логических записей таким образом, чтобы их
формат (длина данных) соответствовал физическому формату хранения. В
случае кратности длин, т. е. если длина логической записи будет кратной
длине кластера или в кластере будет размещаться целое число записей, будет исключена передача данных, не запрошенных текущей операцией.
Непосредственное применение приведенных методов повышения эффективности тем не менее достаточно ограниченно по целому ряду причин. По мере добавления новых типов данных или при появлении новых приложений структура записей должна будет меняться. Требования к обработке изменяются случайным образом. Если возникает необходимость модификации выбранных структур данных, то приходится соответственно переписывать и отлаживать прикладные программы. Чем большее количество прикладных программ имеется в наличии, тем более дорогой становится эта процедура. Кроме того, логическая структура записей стала бы зависимой от параметров физической структуры носителя, и планирование эффективной физической организации для конкретной структуры данных потребовало бы уже знаний системного аналитика.
Практическое решение состоит во введении контролируемой функциональной и информационной избыточности, обеспечивающей сокращение времени доступа за счет: 1) специализации компонент, т. е. упрощения процедур преобразований; 2) построения вспомогательных структур (в той или иной степени дублирующих основную информацию). Основой этого подхода является принцип выделения и представления описательных составляющих в виде самостоятельных операционных объектов, хранимых отдельно от определяемых ими данных.
Методы доступа к записям (конец 60-х гг.)
Этот этап характеризуется изменением природы файлов и устройств. Появляются дисковые устройства с прямым доступом и возможностью обновления «по месту изменений», а программное обеспечение позволяет без перекомпиляции программы изменять расположение набора данных, но без изменения структуры записей и типа организации набора.
Организация хранения и доступа в этом случае характеризуется следующими особенностями:
- логическая и физическая структуры файла различаются между собой,
но взаимосвязь между ними достаточно простая. Запоминающее устройство
можно менять без изменения прикладной программы; - файл создается в прикладной программе как набор данных с
последовательным, индексно-последовательным или с прямым доступом (по физическому адресу). Возможен последовательный или произвольный
доступ к записям (но не к полям). Поиск по многим ключам, как правило, не
используется. Если используются иерархические файлы, то взаимосвязь
«исходный — порожденный» программируется в прикладной программе.
Список литературы
- Вирт Н. Алгоритмы и структуры данных / Пер. с англ. М.: Мир, 1989.
- Зиндер Е. 3. Проектирование баз данных: новые требования, новые
подходы // СУБД. 1996. № 3. - Голицына О. Л. , Максимов Н. В. , Попов И. И. Базы данных/Учебное пособие, 2002.
Свежие комментарии